Artículos
Agros: servicio de búsqueda de información basado en ontología de dominio agropecuario
AGROS: Information search service based on the ontology of the agricultural domain
Revista FAVE Sección Ciencias Agrarias
Universidad Nacional del Litoral, Argentina
ISSN: 2346-9129
ISSN-e: 2346-9129
Periodicidad: Semestral
vol. 21, núm. 2, 12004, 2022
Recepción: 08 Febrero 2022
Aprobación: 02 Junio 2022

Esta obra está bajo una Licencia Creative Commons Atribución-NoComercial-CompartirIgual 4.0 Internacional.
Resumen: La falta de precisión y exhaustividad en los resultados obtenidos al realizar una búsqueda de información es un fenómeno que ocurre con mucha frecuencia. El desarrollo de servicios más efectivos propicia el logro de mejores resultados en las búsquedas de información. Una de las posibilidades que brinda la Web 3.0 son las ontologías y con ellas el surgimiento de servicios basados en ontologías de dominio. Los servicios basados en ontologías de dominio comprenden una estandarización de sus contenidos, así como su interrelación directa con otras informaciones contenidas en la Web. El trabajo tiene como objetivo el diseño de AGROS: servicio de búsqueda de información basado en una ontología de dominio agropecuario. El desarrollo de dicho servicio comprende la modelación de una ontología en Prótegé, de modo que facilita la búsqueda y recuperación de información de relevancia semántica en este dominio de conocimiento. El servicio utiliza consultas SPARQL para mostrar información relevante y generar recomendaciones de forma automática. El alcance del servicio podría ampliarse, para ello se podrían integrar otros recursos de información y fuentes de datos agropecuarios adicionales.
Palabras clave: AGROS, servicio de información, ontología, dominio agropecuario, Prótegé.
Abstract: The lack of precision and exhaustiveness in the results obtained when searching for information is a phenomenon that occurs very frequently. The development of more effective services encourages the achievement of better results in information searches. One of the possibilities offered by Web 3.0 are ontologies and with them the emergence of services based on domain ontologies. Services based on domain ontologies include a standardization of their contents, as well as their direct interrelation with other information contained on the Web. The objective of this work is the design of AGROS: an information search service based on an ontology of the agricultural domain. The development of this service includes the modeling of an ontology in Prótegé, so that it facilitates the search and retrieval of information of semantic relevance in this domain of knowledge. The service uses SPARQL queries to display relevant information and automatically generate recommendations. The scope of the service could be expanded, for which other information resources and additional agricultural data sources could be integrated.
Keywords: AGROS, information service, ontology, agricultural domain, Prótegé.
Introducción
La falta de precisión y exhaustividad en los resultados obtenidos al realizar una búsqueda de información es un fenómeno que ocurre con mucha frecuencia. De esta manera el proceso de búsqueda no le proporciona al usuario final una respuesta contundente. Para que esto no suceda se deben desarrollar aplicaciones más específicas y servicios “más inteligentes”. La web semántica implica el uso de un conjunto de herramientas y tecnologías (Pastor, 2013). Esto posibilita la comprensión tanto para los humanos como para los agentes artificiales que tienen un papel fundamental en la búsqueda y recuperación en línea. A partir de sus objetivos, la web semántica aventaja a la web tradicional en tanto que agrega estructura: reduce las avalanchas de información carentes de significado que la web tradicional ofrece a los usuarios. Permite a las computadoras tareas de inteligencia artificial: al estar sustentada en XML, RDF y OWL la web semántica se torna más significativa y relacional, promoviendo una verdadera gestión del conocimiento a través de los motores de búsqueda (Suárez, 2021, p. 139).
A partir de sus objetivos, la web semántica aventaja a la web tradicional en tanto que agrega estructura: reduce las avalanchas de información carentes de significado que la web tradicional ofrece a los usuarios. “Permite a las computadoras tareas de inteligencia artificial: al estar sustentada en XML, RDF y OWL la web semántica se torna más significativa y relacional, promoviendo una verdadera gestión del conocimiento a través de los motores de búsqueda” (Suárez, 2021, p. 139). Una de las posibilidades que brinda la Web 3.0 son las ontologías y con ellas el surgimiento de servicios basados en ontologías de dominio.
En opinión de Gai, et. al. (2015), la ontología es uno de los modelos de representación del conocimiento más común utilizado ampliamente en la recuperación de información, ya que representa el conocimiento en términos de jerarquías de información legibles por máquina, comprensibles y procesables.
Para León, Ruiz y Mederos (2016) las ontologías son un tema de investigación en varias comunidades y áreas de estudio: la ingeniería de software, las matemáticas, la informática y más recientemente en el campo de las Ciencias de la Información, como herramientas en la representación de información (como esquema conceptual), en búsqueda y recuperación (como herramienta), como sistemas de información cooperativos y su aplicación a bibliotecas digitales y herramientas para la gestión del conocimiento.
En el caso de las Ciencias de la Información, las ontologías han propiciado el desarrollo de servicios de búsqueda de información más efectivos, resulta evidente el potencial desarrollado mediante la web semántica, también conocida como web inteligente, este fenómeno genera avances en diversos campos científicos, por ejemplo, el de búsqueda y recuperación de la información (Coneglian, et. al., 2017).
Los servicios basados en ontologías de dominio comprenden una estandarización de sus contenidos, así como su interrelación directa con otras informaciones contenidas en la Web. El dominio agropecuario es uno de los que más necesita este tipo de servicio, principalmente en lo que respecta al trabajo de los investigadores, sus necesidades de información y conocimiento. Dado que los recursos de información disponibles en dicho dominio se encuentran dispersos en variadas ubicaciones con formatos heterogéneos.
Al referirse a la importancia de las ontologías para el dominio agropecuario, Zheng, et. al. (2012), señalan que la ontología es la representación formal de conceptos y sus relaciones mutuas. Tiene un amplio potencial de aplicación en la clasificación de información agrícola, la construcción de bases de datos de información y conocimiento, la investigación y desarrollo de buscadores inteligentes, así como la realización de servicios de información cooperativa, etc. “En la última década, los expertos de cada área reconocen la importancia y urgencia de construir y aplicar sistemas de organización de información y formas de representar el conocimiento en cada una de sus áreas en un contexto digital, incorporando instrumentos como los tesauros, las clasificaciones y las ontologías” (Lagos, 2020, p. 37).
El presente trabajo tiene como objetivo el diseño de un servicio de búsqueda de información basado en una ontología de dominio agropecuario.
Metodología
Para el diseño del servicio de información: AGROS, se utilizó la metodología de Tramullas y Garrido del 2006, “Planificación, diseño y desarrollo de servicios de información digital”. Esta metodología cuenta con los siguientes elementos:
1. Aspectos para la creación de un servicio de información digital:
-
Entorno del Servicio.
-
Gestión de los Recursos de Información.
-
Modelo Conceptual.
-
Entrenamiento a los Usuarios.
2. Ciclo de vida de un servicio de información digital.
3. Fases y actividades para la creación de un servicio de información digital.
-
Planificación (Misión, declaración de usuarios, metas, objetivos, recursos humanos, recursos tecnológicos, recursos económicos, plan de acción).
-
Diseño conceptual y lógico: indicación y análisis de los requerimientos operacionales, entradas, salidas y procedimientos. Descripción de la arquitectura del sistema y de la interfaz de usuario. Definición de las políticas y determinación de los criterios de calidad.
5. Implantación o desarrollo: adquisición e instalación del hardware, adquisición e instalación del software, creación de un prototipo del servicio. Adquisición y carga de los recursos de información, control del funcionamiento del prototipo. Prueba del prototipo por los usuarios, elaboración del plan final de arquitectura del servicio. Selección y formación del administrador final del servicio. Implementación del servicio de información digital, lanzamiento y promoción del servicio, formación de los usuarios.
6. Mantenimiento: supervisión del funcionamiento del servicio, revisión y actualización. Elaboración de un plan de mantenimiento que debe comprender la subsanación de contingencias correctivas, evolutivas y precedentes, previendo y respondiendo satisfactoriamente a la aparición de nuevas demandas.
7. Evaluación: conocimiento de los factores asociados con el éxito o fracaso de los resultados. Realizar las correcciones necesarias en el servicio de información creado para lograr un mejor funcionamiento y establecer ajustes en proyectos futuros. Aunque es necesario destacar que la evaluación debe estar presente en mayor o menor medida en el resto de las fases. Ya que es una herramienta de apoyo para la realización de las demás actividades.
En la investigación se realiza el diseño de AGROS, con énfasis en la creación de la ontología de dominio agropecuario que constituye su principal recurso tecnológico. Además, contempla especificaciones a tener en cuenta sobre los usuarios potenciales que son profesores e investigadores de la Facultad de Ciencias Agropecuaria (FCA) de la Universidad Central “Marta Abreu” de Las Villas (UCLV). Asimismo, comprende aspectos como los recursos informacionales, económicos y tecnológicos.
Para el desarrollo de la ontología se emplearon los siguientes pasos:
-
Determinar el dominio y el alcance de la ontología.
-
Enumerar términos importantes.
-
Definir las clases y la jerarquía de clases.
-
Definir propiedades de las clases.
-
Crear instancias.
La principal herramienta empleada fue el software Prótegé 4.3 para la modelación e implementación de la ontología. Prótegé es un editor de ontologías de código abierto creado por la Universidad de Stanford. El mismo, se utiliza como herramienta para crear ontologías en un formato estandarizado, como OWL o RDF, y permite compartir y utilizar otras aplicaciones y plataformas. Para Adi, et. al., (2009) OWL es una extensión de RDF, utiliza las mismas tripletas, aunque tiene mayor expresividad y funcionalidad a la hora de expresar el significado y la semántica.
Fueron utilizados varios softwares para la creación, procesamiento y refinamiento de la información a incorporar a la ontología, entre ellos:
-
Drupal: es un gestor de contenidos de acceso abierto, multipropósitos y muy dinámico. Permite almacenar sus contenidos en archivos estáticos en el sistema de ficheros del servidor de forma fija, el contenido textual de las páginas y otras configuraciones son almacenados en una base de datos y se editan utilizando un entorno Web. Posibilita la creación del sitio sobre el cual se monta el servicio. Por su parte, Chang y Blanco (2019), afirman que Drupal es un sistema de gestión de contenido de código abierto (CMS) que facilita un rápido despliegue de estas aplicaciones web.
-
Bizagy Process Modeler: este software libre permite diagramar, documentar y simular procesos de manera gráfica en un formato estándar conocido como BPMN (Business Process Modeling Notation). “Se centra en la forma que el trabajo debe ser realizado, y las maneras en que los documentos de los procesos pueden ser reestructurados para mejorar su eficiencia” (Germania, 2020, p. 20). Los procesos y su documentación correspondiente pueden exportarse a Word, PDF, Visio o SharePoint para compartirlos y comunicarlos. Según el Glosario Bizagy (2022) es la notación gráfica estándar que describe los pasos lógicos en un Proceso de negocio. Esta notación ha sido especialmente diseñada para coordinar la secuencia de los Procesos y los mensajes que fluyen entre los participantes en las diferentes actividades.
-
Edraw Max: es un programa de diagramación muy versátil, con características que lo hacen perfecto no sólo para diagramas de aspecto profesional de flujo, organigramas, diagramas y gráficos de negocios, sino también diagramas de red, planos de construcción, mapas mentales, flujos de trabajo, diseños de moda, diagramas UML, esquemas eléctricos de ingeniería, etc.
-
Authoris: permite la transformación de los datos de las ontologías en registros de autoridad, y utilizar las prestaciones de Silk para gestionar datos enlazados. También los gestiona en triple stores descargados de formatos HTML. Al respecto Senso, Leiva y Domínguez (2013) expresan, Authoris se basa en Drupal e incorpora los protocolos de Dublin Core, SIOC, SKOS y FOAF.
-
Pubby: es un servidor que facilita la conexión y gestión de los triples stores, conectándolos con fuentes de datos externas. Así no resulta necesario lanzar constantes consultas SPARQL a diversos Endpoints. Esta herramienta convierte los SPARQL Endpoints en servidores de Linked Data. También facilita la visualización de datos HTML y las consultas de tripletes en este formato. Esta aplicación trabaja en Java, por lo que es necesario emplear el software servidor Apache Tomcat.
-
Silk: sirve para la construcción de enlaces de datos en recursos disímiles, uniendo los enlaces RDF de las fuentes particulares con otras fuentes de datos. Dispone de: una consola para realizar enlaces entre dos datasets y un servidor http capaz de recibir datos e introducirlos en el flujo RDF a través de data ítems. “La flexibilidad y calidad de los datos que gestiona el lenguaje Silk-LSL permite adaptarlos a la filosofía de trabajo de Linked Data” (León, Ruiz y Mederos, 2016, p. 7).
-
Metharto: Según Hidalgo-Delgado y Rodríguez (2013) es una herramienta capaz de extraer los metadatos de archivo y los elementos de SKOS del proveedor de datos soportado en OAI-PMH.
-
Open Link Virtuoso: servidor universal que combina las funcionalidades de los tradicionales RDBMS, ORDBMS, bases de datos virtuales, RDF, XML, y que facilita el uso de texto libre en aplicaciones web (Haslhofer y Schnadl, 2008).
-
D2RQ: lenguaje de mapeo que lleva a cabo la relación entre bases de datos y lenguajes semánticos RDF y vocabularios OWL. Es capaz de transformar un documento RDF en la estructura sintáctica de turtle. Los mapas que se generan con este lenguaje definen un grafo en RDF donde se incluye toda la información de la base de datos al igual que en SQL, solo que los datos generados en la estructura del RDF siempre van a exigir tablas relacionales virtuales. Se puede acceder a la plataforma RDF de varias formas según las necesidades de implementación. Por ejemplo: acceso a SPARQL, al servidor para datos enlazados, a un almacén de datos RDF, a una interface simple para RDF que convierte los datos bibliográficos en el formato de LIAM, y a una API de Jena capaz de interoperar las bases de datos en DR2Q (Bizer y Seaborne, 2004).
Resultados y discusión
AGROS: servicio de búsqueda de información basado en ontología
El objetivo del servicio es ofrecer información de interés, generada en el ámbito agropecuario, facilitando el desarrollo de investigaciones y logrando suplir las necesidades informativas de los usuarios. El servicio permitirá resultados en la búsqueda y recuperación de información de mayor relevancia y exhaustividad. Mientras que la creación de contenidos semánticos y las representaciones en RDF de identificadores posibilitan que cualquier usuario se beneficie al utilizarlo.
Indicaciones sobre la comunidad usuaria: el servicio se extiende hacia toda la comunidad universitaria de la UCLV, aunque sus usuarios potenciales, a los cuales está encaminada la realización del mismo, son los profesores e investigadores de la FCA. Estos últimos, son los más interesados en las temáticas a las cuales se encuentra dirigido AGROS.
Para el diseño e implementación del servicio es necesario el trabajo de dos tipos de especialistas, encaminados a determinar los recursos informacionales, económicos y tecnológicos, los mismo son de las áreas:
-
Ciencias de la información: se encargan del trabajo con los usuarios, de la determinación de las necesidades académico-informativas y de los requerimientos necesarios para el diseño del servicio.
-
Ciencias de la Computación: son responsables de diseñar el sistema de navegación, búsqueda y etiquetado, cuentas de usuarios, así como la designación de permisos de administración y mantener el funcionamiento tecnológico.
Las habilidades computacionales y de análisis de información, deben estar presentes en todos los especialistas encargados. En lo que respecta a los recursos de información, el servicio aprovecha fundamentalmente:
-
AgroPortal, repositorio para alojar, buscar, versionar y alinear ontologías y vocabularios agrícolas (Jonquet, et. al., 2018).
-
Base de Datos AGRIS, contiene información bibliográfica especializada en las ciencias agropecuarias y afines. Incluye monografías, informes técnicos, tesis, artículos y otras tipologías documentales de instituciones del área agrícola, conocida también como “AGRIS de la FAO” (FAO, 2022).
-
Tesauro Agrícola Multilingüe AGROVOC, es un tesauro relevante publicado como datos abiertos vinculados sobre alimentación y agricultura, disponibles para el uso públicos. Ofrece una colección estructurada de conceptos, términos, definiciones y relaciones agrícolas que se utilizan para identificar recursos de manera inequívoca, permitiendo procesos de indexación estandarizados y haciendo que las búsquedas sean más eficientes. AGROVOC utiliza tecnologías web semánticas, conectándose a otros sistemas de organización del conocimiento multilingües y construyendo puentes entre conjuntos de datos (FAO, 2022).
-
National Agricultural Library (NAL), es una de las cinco bibliotecas nacionales de los Estados Unidos. Alberga una de las colecciones más grandes del mundo dedicadas a la agricultura y sus ciencias relacionadas. Contiene un gran número de recursos y fuentes primarios para la investigación en el campo de la agricultura.
Además, se trabajará con el repositorio institucional de la UCLV, que comprende toda la producción científica del centro. Dentro de este se pueden encontrar las tesis de diploma, maestría y doctorado, los artículos publicados por al menos un investigador perteneciente a la institución en las diversas revistas y bases de datos nacionales e internacionales, así como los artículos publicados en las revistas Centro Agrícola, Centro Azúcar y Biotecnología Vegetal. En este repositorio están representadas las más disímiles temáticas y por supuesto entre ellas la agrícola.
El diseño conceptual y lógico comprende elementos imprescindibles (incluyendo el trabajo con los recursos informacionales, económicos y tecnológicos) como las actividades que deben desempeñar los especialistas que conforman el servicio. Por ello, se modelaron las tareas a realizar para la creación de este servicio como se puede ver en la Figura 1.
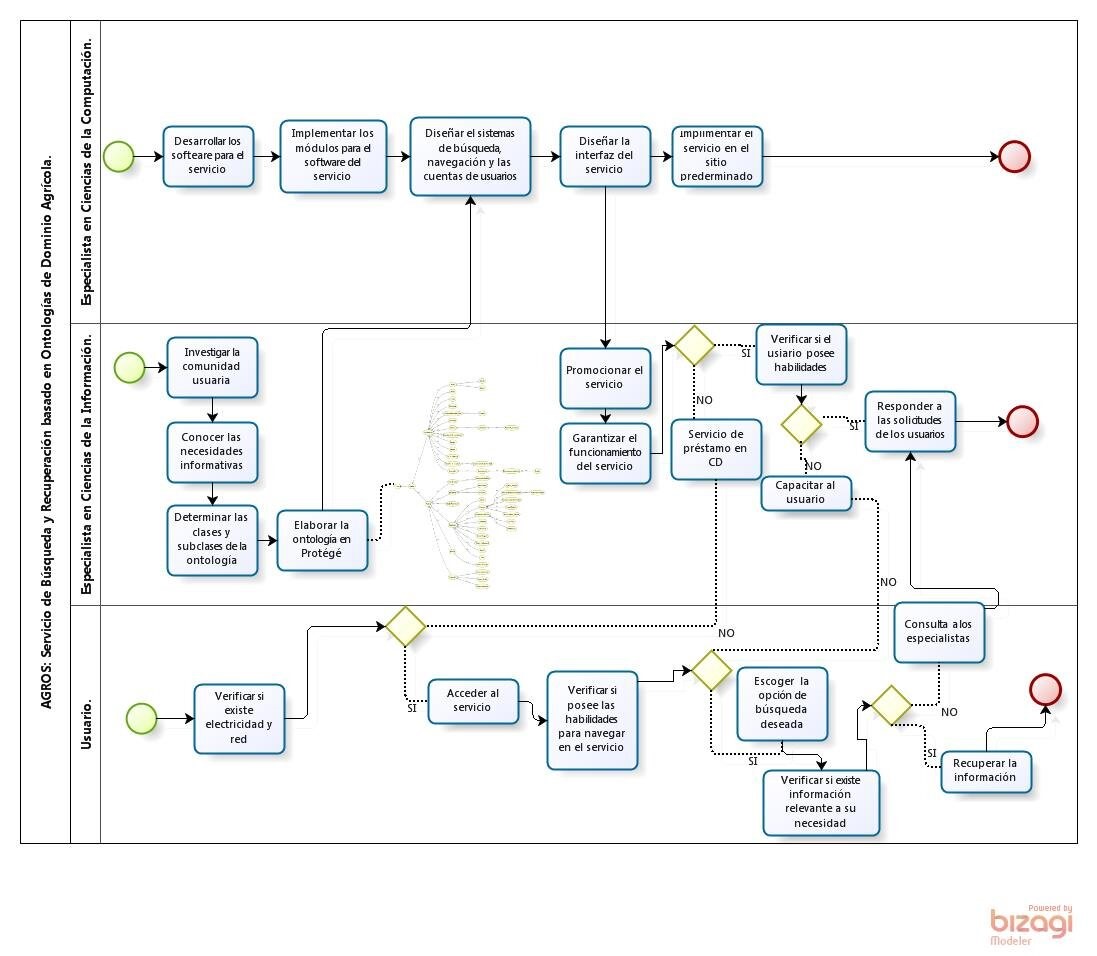
Figura 1 / Figure 1
Modelación conceptual y lógica de las tareas a realizar para la creación de AGROS. / Conceptual and logical modeling of the tasks to be carried out for the creation of AGROS.
elaboración propia. / self made.
Entre los principales roles en el diseño de AGROS encontramos el del Especialista en Ciencias de la Información. Este debe centrar su atención en la realización de estudios de necesidades de los futuros usuarios potenciales. Así, una vez conocidas dichas necesidades, determinar con el uso de leguaje controlado las clases y subclases que debe contener la ontología, para una mejor búsqueda y recuperación de la información en el servicio. Igualmente tiene dentro de sus responsabilidades la difusión del servicio, la formación de usuarios y la vigilancia a las necesidades de información solicitadas.
Las entradas del servicio serán los documentos que responderán a las necesidades informacionales y toda la información que sobre estos se derive, como los metadatos, etc., además de las solicitudes o búsquedas que realizan los usuarios. También se entrarán los datos del administrador, de los usuarios y las taxonomías que en conjunto con los datos anteriormente mencionados contribuirán a la formación de la ontología.
Las salidas del servicio estarán constituidas por los documentos recuperados por los usuarios, así como un listado con los títulos de la documentación y de las temáticas en las cuales estos investigan, la cual tendrá un nivel de actualización.
Para la creación del servicio será necesario contar con recursos económicos, los mismos giran alrededor del hardware, software y el pago al personal necesario para la implementación del servicio. El monto para estas actividades debe cubrir las necesidades en cuanto a:
-
Computadoras.
-
Servidor “premium” o de alta gama.
-
Impresora láser.
-
Pago a Especialistas en Ciencias de la Información.
-
Pago a Especialistas en Ciencias de la Computación.
Ontología de Dominio Agropecuario
En este caso, el recurso tecnológico por excelencia para el desarrollo del servicio es la ontología de dominio agropecuario. Las ontologías han demostrado su utilidad en diferentes escenarios. Sin embargo, todavía surgen problemas en el diseño, construcción y mantenimiento con términos específicos de dominio y relaciones conceptuales no taxonómicas. El procesamiento del lenguaje natural y las técnicas de aprendizaje de ontologías son necesarios para construir y mantener la ontología específica de dominio.
La ontología fue diseñada en el editor ontológico Prótegé, un software de código abierto creado por la Universidad de Stanford como herramienta para crear ontologías en un formato estandarizado, como OWL o RDF, el cual permite compartir y utilizar otras aplicaciones y plataformas. Se presta especial atención a las clases, ya que algunas de las que comprende la ontología son las diferentes opciones de búsqueda, así como las temáticas más solicitadas que posee el servicio una vez configurado su diseño. La Figura 2 muestra una vista general de las clases de la ontología.
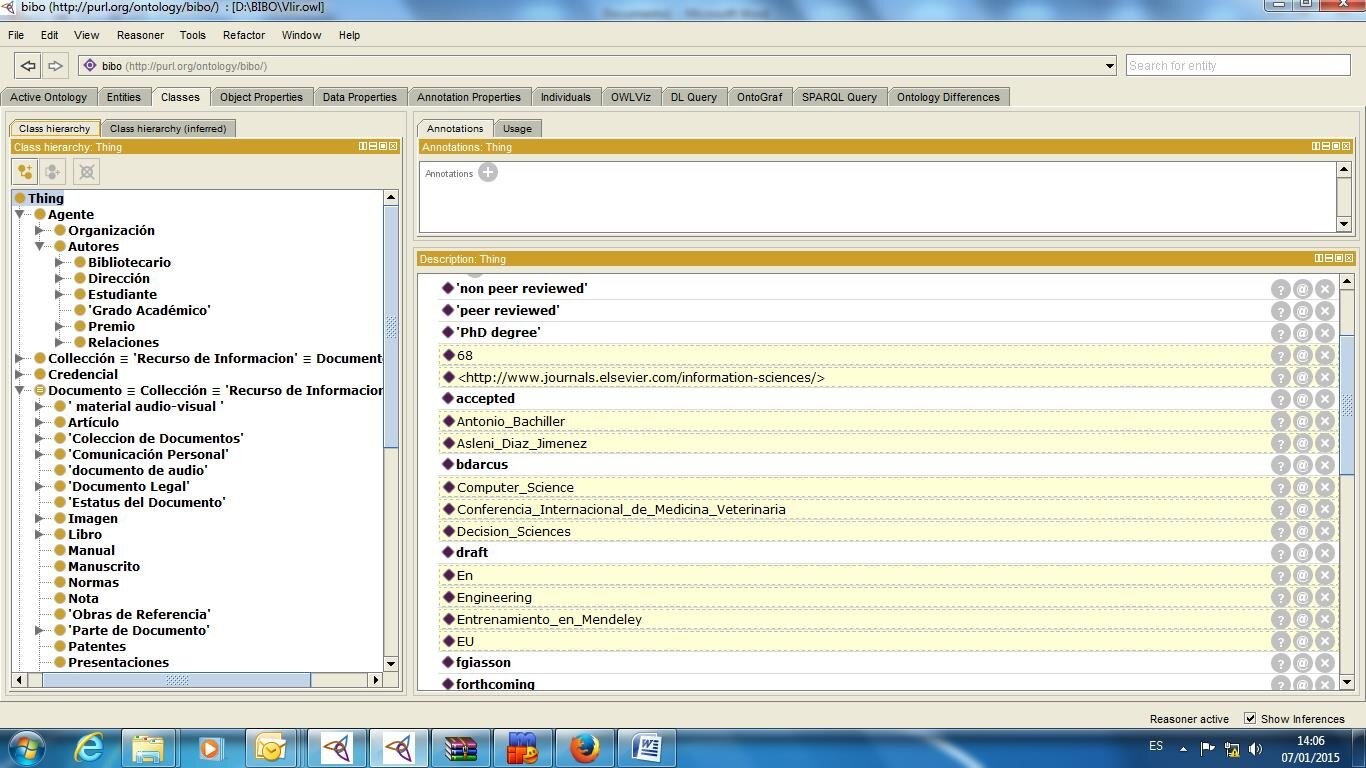
Figura 2 / Figure 2
Vista general de las clases de la ontología en Prótegé. / General view of the ontology classes in Prótegé.
elaboración propia. / self made.
Para generar las búsquedas facetadas de ontologías se utiliza una versión modificada de la propuesta descrita por Cooper, et. al. (2013). El gran problema de Drupal para la gestión de ontologías es su apego a vocabularios específicos de tratamiento de datos. Lenguajes de ontologías como SKOS, Dublin Core o SIOC son ineficientes cuando se trata de búsqueda de información federada. La elaboración de consultas se puede realizar de forma más completa, explotando las posibilidades de la transitividad y la simetría cuando se trata de localizar información en varios recursos usando SPARQL.
A su vez, SPARQL es el estándar de consulta lenguaje para RDF, compuesto por patrones gráficos básicos extendidos con características expresivas que incluyen expresiones de ruta, álgebra relacional, agregación, federación, entre otros. La adopción de RDF como modelo de datos y SPARQL como lenguaje de consulta ha crecido significativamente en los últimos años. (Salas y Hogan, 2021, p. 22)
El módulo de búsqueda utiliza los elementos de OWL y los enlaces de igualdad y de exclusión del lenguaje para establecer nuevas consultas dirigidas a puntos específicos de la estructura OWL. De manera que se pueda acceder a diferentes recursos de información situados en bases de datos remotas. OWL2 tips usa SPARQL Enpoints remotos capaces de enlazar las consultas con cada dependencia del repositorio de la universidad.
La información se extrae de las consultas realizadas en lenguaje SPARQL con ayuda de los constructores utilizados en la definición de la ontología, combinados con las propiedades OWL: same, OWL: equivalent Class, OWL: equivalent Property, OWL: different From y OWL: All Different como enlaces. El proceso de indexación está precoordinado para facilitar la recuperación de información, quedando preestablecidas las funcionalidades que enlazan los recursos. Todo ello gracias al procesador distribuido de SPARQL. Es posible utilizar información pre-indexada para las nuevas consultas que entran en la plataforma y distribuir búsquedas derivadas de consultas generales, de acuerdo con las necesidades de los usuarios potenciales de AGROS.
La conformación de la ontología de manera gráfica permite una mejor comprensión del alcance de la misma, como se puede ver en la Figura 3. De esta manera se pueden detectar errores con mayor facilidad en cada uno de sus componentes, principalmente en las relaciones.
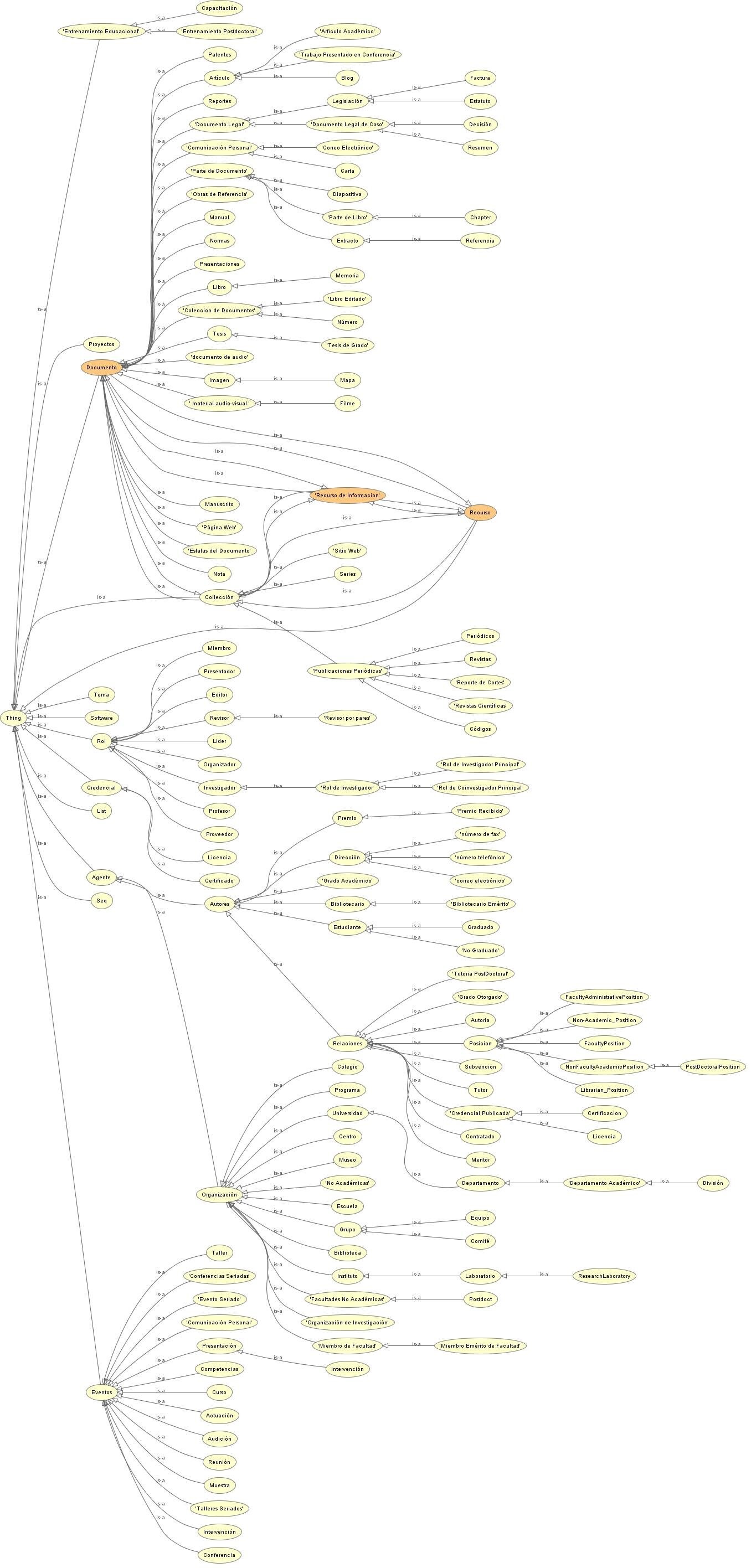
Figura 3 / Figure 3
Esquema de la ontología. / Scheme of the ontology.
Elaboración propia. / Self made.
Conclusiones
El servicio AGROS, basado en ontología, se crea con la intención de ofrecer respuestas lo más oportunas posibles a las consultas formuladas. El mismo pretende el logro de mayor relevancia y exhaustividad en los resultados de la búsqueda y recuperación de información. Se utilizan consultas SPARQL para mostrar información relevante y generar recomendaciones de forma automática.
El alcance del servicio podría ampliarse, ya que su enfoque no se limita estrictamente a su caso de uso inicial, es decir, los usuarios de la UCLV. Para ello se podrían integrar otros recursos de información y fuentes de datos agrícolas adicionales.
Por último, cabe señalar que este y otros trabajos podrían simplificarse si diversas organizaciones proporcionaran sus datos como recursos semánticos. Además, esto permitiría actualizar la ontología existente con nuevos conceptos y sus relaciones.
Referencias bibliográficas
Adi, K., Bouzida, Y., Hattak, I., Logrippo, L. y Mankovskii, S. (2009, May). Typing for conflict detection in access control policies. In International Conference on E-Technologies (pp. 212-226). Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-01187-0_17
Bizer, C. y Seaborne, A. (2004, November). D2RQ-treating non-RDF databases as virtual RDF graphs. In Proceedings of the 3rd international semantic web conference (ISWC2004) (Vol. 2004). Hiroshima: Springer. https://files.ifi.uzh.ch/ddis/iswc_archive/iswc/ab/2004/iswc2004.semanticweb.org/posters/PID-SMCVRKBT-1089637165.pdf
Coneglian, C. S., Dieger, R., Segundo, J. E. S., y Capretz, M. (2017). O papel estratégico da web semântica no contexto do big data. https://repositorio.ufsc.br/bitstream/handle/123456789/180289/ST2.4.pdf?sequence=1&isAllowed=y
Cooper, L., Walls, R. L., Elser, J., Gandolfo, M. A., Stevenson, D. W., Smith, B., ... y Jaiswal, P. (2013). The plant ontology as a tool for comparative plant anatomy and genomic analyses. Plant and Cell Physiology, 54(2), e1-e1. https://doi.org/10.1093/pcp/pcs163
Chang, L. R., y Blanco, L. A. (2019). Fortalecimiento de la seguridad en drupal sin utilizar complementos. Serie Científica de la Universidad de las Ciencias Informáticas, 12(9), 56-72. https://publicaciones.uci.cu/index.php/serie/article/view/479
FAO. (2022). AGRIS. https://www.fao. org/agris/about
FAO. (2022). New release of the AGROVOC Thesaurus. AGROVOC. https://www.fao.org/agrovoc/news/may-2022-new-release-agrovoc-thesaurus
Gai, K., Qiu, M., Jayaraman, S. y Tao, L. (2015). Ontology-based knowledge representation for secure self-diagnosis in patient-centered teleheath with cloud systems. In 2015 IEEE 2nd International Conference on Cyber Security and Cloud Computing. 2015: 98-103. https://doi.org/10.1109/CSCloud.2015.72
Germania, A. V. A. (2020). Automatización del proceso de evaluación de los trabajadores a través de la plataforma Bizagi. Revista Ibérica de Sistemas e Tecnologias de Informação, (E27), 41-53. https://www.researchgate.net/profile/Leonardo-Dominguez/publication/39898103_Generacion_de_Servicios_Digitales_en_Ciudades_Inteligentes_a_Partir_de_las_Capacidades_de_los_Sistemas_de_Camaras/links/5e6aeb57a6fdccf321d92bd8/Generacion-de-Servicios-Digitales-en-Ciudades-Inteligentes-a-Partir-de-las-Capacidades-de-los-Sistemas-de-Camaras.pdf#page=62
Glosario Bizagi. (2022). Software gratuito de mapeo y modelamiento de procesos de negocio - Bizagi Glosario. https://help.bizagi.com/bpm-suite/es/index.html?glossary.htm
Haslhofer, B., y Schandl, B. (2008, January). The OAI2LOD Server: Exposing OAI-PMH metadata as linked data. In LDOW.
Hidalgo-Delgado, Y., y Rodríguez, R. (2013). La Web Semántica: una breve revisión. Revista Cubana de Ciencias Informáticas, 7(1), 76-85. http://scielo.sld.cu/pdf/rcci/v7n1/rcci09113.pdf
Jonquet, C., Toulet, A., Arnaud, E., Aubin, S., Yeumo, E. D., Emonet, V., Graybeal, J., Laporte, M. A., Musem, M. A., Pesce, V. y Larmande, P. (2018). AgroPortal: A vocabulary and ontology repository for agronomy. Computers and Electronics in Agriculture, 144, 126-143. https://doi.org/10.1016/j.compag.2017.10.012
Lagos, O. K. (2020). Sistema de ayuda a la decisión basado en ontologías para el diagnóstico y prevención de las enfermedades en cultivos (Doctoral dissertation, Universidad de Murcia).https://digitum.um.es/digitum/bitstream/10201/94672/1/TesisKattyLagosOrtiz.pdf
León, Y. R., Ruiz, J. A. S. y Mederos, A. A. L. (2016). Diseño de una ontología para la gestión de datos heterogéneos en universidades: marco metodológico. Revista Cubana de Información en Ciencias de la Salud (ACIMED), 27(4). http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S23071132016000400010&lng=es&nrm=iso
Pastor, J. A. (2013). Tecnologías de la web semántica. Editorial UOC. https://books.google.es/books?id=dNAtAwAAQBAJ&lpg=PT4&ots=kjX340bZhb&dq=La%20web%20sem%C3%A1ntica%20implica%20el%20uso%20de%20un%20conjunto%20de%20herramientas%20y%20tecnolog%C3%ADas%20%20Pastor%202011&lr&hl=es&pg=PP1#v=onepage&q&f=false
Salas, J., y Hogan, A. (2021). Semantics and Canonicalisation of SPARQL 1.1. Semantic Web, (Preprint), 1-65. https://doi.org/10.3233/SW-212871
Senso, J. A., Leiva, A. A., y Domínguez, S. E. (2013). Nexus: Sistema para facilitar la difusión de la información en las bibliotecas universitarias. http://dx.doi.org/10.3145/epi.2012.ene
Suárez S., A. (2021). Web vs web semántica: métodos distintos de organización de información en la red. https://ru.iibi.unam.mx/jspui/bitstream/IIBI_UNAM/146/1/ 08_informacion_despues_adriana_suarez.pdf
Zheng, Y. L., He, Q. Y., Ping, Q. I. A. N., y Ze, L. I. (2012). Construction of the ontology-based agricultural knowledge management system. Journal of Integrative Agriculture, 11(5), 700-709. https://doi.org/10.1016/S2095-3119(12)60059-8

